의료 인공지능
전문가 양성과정

치매와 영상 기반 인공지능 연구에 대한 소고: 의료 인공지능 전문가 양성과정 경험 소개
강원대학교병원 신경과 장재원
대한치매학회 홈페이지 회원공간에는 대한치매학회 회원들에게 도움이 될 수 있는 많은 내용들이 업데이트 되었습니다. 무엇이 어떻게 업데이트 되었는지 알아볼까요?
서론
최근 인공지능은 연구의 영역을 넘어서 일반 생활 속에도 파고 들고 있으므로, 그것이 측정하고, 분석하고, 정의하며, 추진해 나아가는 큰 흐름에서 어떤 분야도 자유롭다고 하기 어려울 것 같다. 현재 치매 연구에 있어 가장 주목받는 연구 방법에는 데이터과학, 뇌영상 및 Omics로 대변되는 생물의학적 접근이 포함된다. 이러한 방법들은 인공지능 방법론을 바탕으로, 뇌과학 연구를 포함한 인간 질환의 전반을 연구하는 강력한 도구로 집대성 되고 있다. 실제, 한국연구재단 키워드에도 빅데이터, 머신러닝, 딥러닝과 같은 인공지능 관련 연구가 크게 늘어 정부 과제의 핵심 트렌드가 되어 가고 있다. 따라서, 최신 연구 방법론에 관심이 많은 연구자들은 각종 심포지엄이나 워크숍 및 국가 기관에서 제공하는 다양한 교육 과정을 통해 해당 기술들을 접해 본 바가 있을 것이다. 본 원고에서는 2019년 처음으로 진행된 ‘1기 의료 인공지능 전문가 양성과정’에서의 경험을 바탕으로 의료인 관점에서의 인공지능 기술을 연구에 활용하는 부분에 대해 개인적 소고를 간단히 적어보았다.
본론
의료 인공지능 전문가 양성과정
보건복지부, 한국보건복지인력개발원 및 대한의료인공지능학회가 주축이 되어 2019년 7월부터 12월까지 진행한
교육과정이다. 교육목적은 의료 패러다임 변화에 따른 빅데이터 및 인공지능 전문가를 양성하여 의료 현장의
실제적인 문제를 다루는 의료 인공지능 모델 개발을 수행하는 것이었다. 교육시간은 총 200시간이었고 대부분
참가자가 임상의사였으며, BT(Biotechnology) 전공자, IT 및 통계 전공자도 포함되어 있었다. 주요 교육내용은
인공지능의 기초, 의료 적용 사례, 인공지능을 적용한 의료영상 분석, 생체신호 분석 및 전자의무기록(EMR)분석으로
구성되었다(https://hie.kohi.or.kr/course/active/detail.do?currentMenuId=003003&courseActiveSeq=5000&courseMasterSeq=1310&cate).
특이사항으로는, 본 교육의 가장 핵심적인 과정이라고 할 수 있는 ‘팀 프로젝트’가 마지막 5주 동안 진행되어, 앞서
진행된 강의와 워크숍을 넘어 실제 임상적 의미가 있는 문제에 대해 인공지능 솔루션을 개발하는 프로젝트를 경험해
볼 수 있었다. 총6개의 팀별 프로젝트가 진행되었으며 그 중 ‘뇌 영상을 이용한 치매 진단 알고리즘 개발’프로젝트에
참여했다.
팀프로젝트 소개
딥러닝을 이용한 뇌영상 기반 치매 알고리즘 개발 프로젝트에 참여하기를 희망한 조원들을 대상으로 서울 아산병원
MI2RL(Medical Imaging & Intelligence Reality Lab.) 연구진의 도움으로 팀과제를 진행하였다.
연구 개요를 간략히 소개하면 공개 데이터인 ADNI의 3D-T1 뇌영상만을 바탕으로 영상 전처리, 딥러닝 네트워크
훈련, 모델의 수정 과정을 거쳐 정상인과 치매를 구분하고 경도인지장애의 치매 예측 모델을 만드는 것으로, 딥러닝
전반을 경험하기 위해 단순한 모델을 설정했다.(그림)
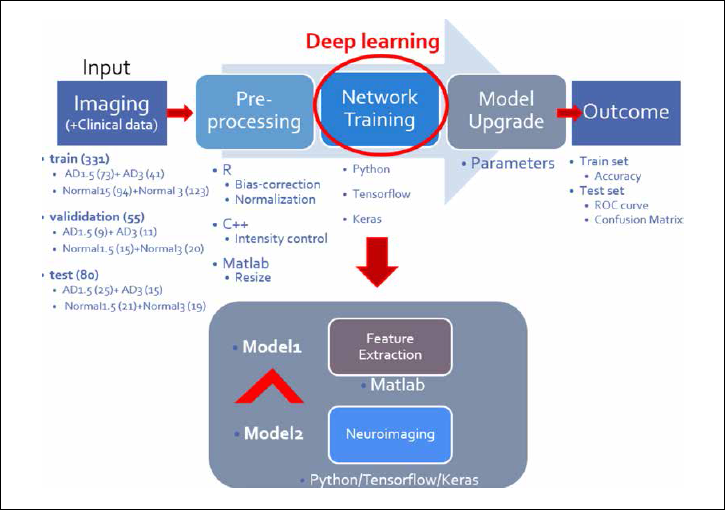
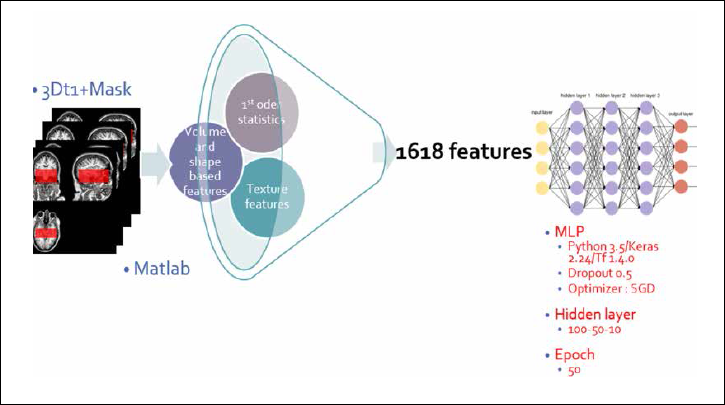
참담한 실패의 결과
결론적으로 5주간의 팀프로젝트는 실패였다. 정상인과 알츠하이머를 구분하는 이진 분류에 있어 Mean ROC곡선의
AUC값이 0.54로 나오는 터무니 없는 결과가 나왔으며, 심지어 3D-CNN(VGG16)이라는 영상 인식 기법을 활용한
학습에서는 아예 결과가 나오지 조차 않았다.
비영상 자료를 사용한 다른 조와 달리 팀프로젝트가 실패한 원인을 꼽자면 끝없는 에러의 발생을 들 수 있을 것 같다.
영상 데이터를 다운로드 받는 과정까지는 에러가 없었으나 전처리 과정에서는 매 단계마다 에러가 발생했다. 예를
들어, 전처리에 활용한 R 소프트웨어의 경우 윈도우OS에서는 전처리를 위한 특정 팩키지가 깔리지 않았고 오직
리눅스 환경에서만 해당 처리가 가능하다는 사실을 수 많은 오류를 통해 확인하였다.
MATLAB에서는 이유를 알 수 없는 Segmentation 코드 에러가 났고 이 부분은 프로젝트가 끝나고도 이유를 알 수
없었다. 수십 기가 단위의 뇌영상으로 딥러닝을 시키다 보니 개별 PC에서 학습을 하게 되면 과도한 시간이 소모될
것으로 추정되어 서버를 기반으로 학습을 진행하였는데 서버 접속이 윈도우를 쓰는 사용자들에게는 원활히 되지
않고 맥북사용자에게만 가능하여, 이 부분도 해결 하는데 많은 시간이 소모되었다.
이후의 과정에서도 코딩 에러가 무수히 발생해서 5주의 팀프로젝트를 에러 해결에 대부분 소모한 나머지, 결국
어디서도 보기 힘든 ACU값으로 귀결될 수 밖에 없었다. 딥러닝이라는 학습을 해야 하는데 학용품을 고치는데
대부분의 시간을 소모한 모양새였다.

결론
인공지능 프로젝트에서의 임상 의사의 역할에 대해 고민해 볼 수 있는 시간이었다. 팀프로젝트 이전의 워크숍에서는
강사 분들이 전처리를 마친 정제된 데이터를 제공하고, 이미 검증된 코드를 사용해서 진행되기 때문에 큰 무리없이
학습을 해 볼 수 있었다.
반면에, 실제로 데이터를 바탕으로 전처리 과정부터 진행을 하게 되면, 앞서 기술한 것과 같은 무수한 크고 작은
에러가 초기 세팅 시에는 거의 필연적으로 발생하게 되고 이러한 부분을 임상의가 직접 하나하나 고치는 것이
기술적으로 쉽지 않을 뿐더러 해당 작업에 소모되는 시간이라는 기회비용도 너무 크다고 본다.
따라서, 학습에 사용하는 데이터의 종류에 따라 차이는 존재하겠지만, 인공지능 연구를 진행하려는 임상의 관점에서
앞으로 사용자 친화적인 인공지능 기법이 개발되기 전까지는 기구축된 분석 환경을 가지고 있는 공학자들과의
적극적인 협업을 통해 연구를 하는 것이 옳다고 판단된다. 직접 코딩을 통해 모델을 구축하는 작업은 앞으로의
협업을 위해, 상대 분야에 대한 이해의 폭을 넓히는 과정으로 받아 들이는 것이 효율적이라고 본다.
이러한 이해를 바탕으로 임상의사는 양질의 정형/비정형 데이터를 확보함과 동시에 본인의 도메인 지식으로 연구의
큰 틀을 잡아 주는 역할을 하는 것이 가장 중요한 것 같다. 저만치 앞서나가는 기술 기반의 딥러닝과 실제 임상의가
필요로 하는 의미 있는 기술에 대한 미충족 요구와의 간격이 작지 않다고 생각한다.